




虽然之前也依据tvm官方文档写过一篇关于TVM架构的博客,但总感觉属于一种身在此山中的感觉(偏向于TVM实现的各个模块),并没有一览众山小的即视感(对框架的整体理解)。
因此,今天再次请求出战...
------华丽的分割线------
首先呢,想先来介绍下常规编译器的结构和特征
常规的编译器通常是由前端(frontend)、优化器(optimizer)、和后端(backend) 三部分组成。
编译过程以高级语言作为输入,
PS:
转换过程中,尽量使用目标机器的特殊指令,提高机器代码的性能。
这样划分的好处:
这种设计简化了编译器的组成结构,降低了编译器的开发难度。编译开发者只需要知道如何将高级语言转换为优化器能够理解的中间代码即可,不需要精通优化器的工作原理和目标机器的体系结构。
当系统需要支持新的高级语言,只需要添加相应的编译器前端即可;
当系统需要支持心的目标机器,只需要添加相应的编译器后端即可;

IR(Intermediate Representation) 即中间表示,是用于表示中间代码的数据结构。设计IR的目的是保证编译器的跨平台,因此,去除了硬件平台相关的特性,对于不同的硬件平台,使用相同的IR表示,这位系统支持新语言或新硬件提供了便利
IR既是连接前端和后端的桥梁,又是前端和后端解耦合的工具。
优化器的转换和优化都是围绕IR实现的。
AI编译器又需要解决哪些问题呢?又是什么催生出了AI编译器呢?
先来看个图:
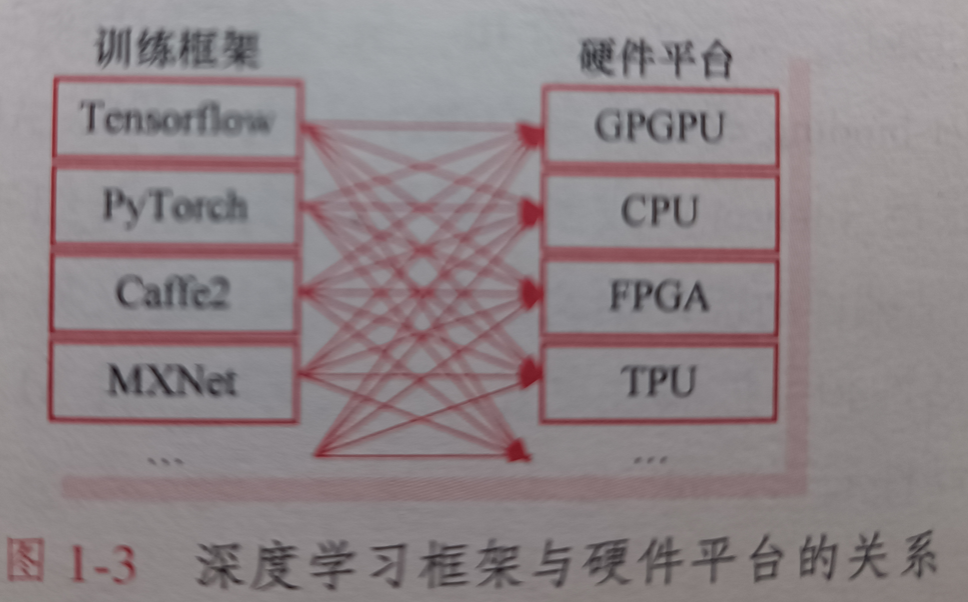
可以发现,训练框架众多,对应到的硬件平台众多,这就导致不同的深度学习框架训练出的模型不能通过某个工具转换生成可部署到不同硬件平台,对框架之间转换以及维护不同后端并保证所有硬件平台性能稳定都是一个巨大的挑战。
AI领域有众多的深度学习框架(Tensorflow、Pytorch等),由于前端接口和后端实现之间的差异,AI模型开发者常常面临从一个框架到另一个框架的巨大困难。
AI模型开发者希望,来自底层DSA(Domain Specific Architecture)改进带来的性能增益能在第一时间反应在模型性能的提升上
框架开发者也面临着同时维护多个后端并保证所有硬件平台性能的坚巨任务。
因此为了解决这些问题,提出了AI编译器,AI编译器的作用如下图:
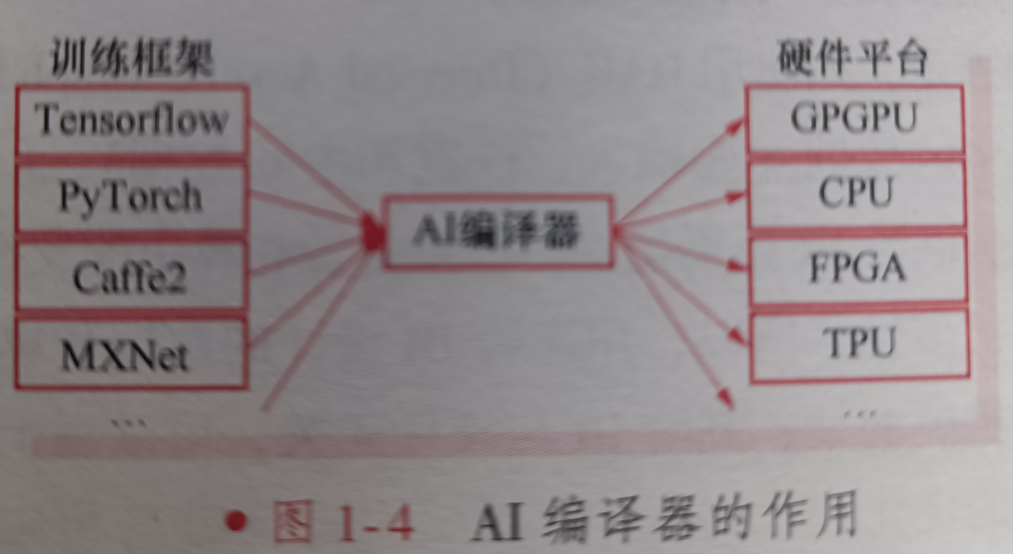
虽然AI编译器还处于发展阶段,还未形成通用的AI编译器技术框架,但通过分析,不难发现AI编译器的体系结构一般仍采用分层设计,作用和常规编译器相似,主要包括编译器前端、IR和编译器后端。
AI编译器结构如下:
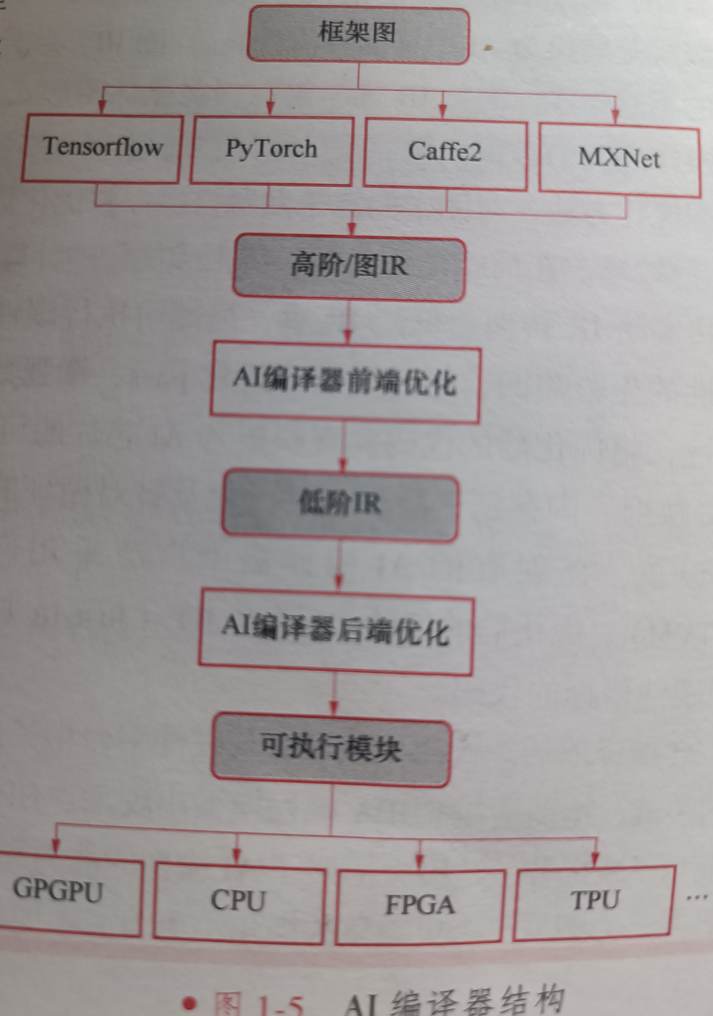
其中IR同样起到了连接前端和后端的作用。
通常,IR是程序的抽象,可用于程序优化。但,由于AI应用的特殊性,AI编译器不仅要解决跨平台问题,还要在兼顾专用架构设计特性的同时,解决深度学习网络本身的优化问题。所以,单层IR已经不能满足需求了。
因为单层IR很难从低阶IR中抽取AI模型的高阶概念,,并以此辅助后端优化。
例如,LLVM很难从低阶IR中的循环指令理解为卷积。
因此,在AI编译器中采用了多阶IR(multi-level IR)设计。多阶IR设计和针对AI模型的特定优化设计正是AI编译器的独特之处。
AI模型被AI编译器转换为多阶IR,其中的高阶IR服务于前端(执行硬件无关的转换和优化),低阶IR服务于后端(执行硬件相关的编译、优化和代码生成)
- 高阶IR的设计重点在于如何抽象计算和控制流,有了这种抽象能力,高阶IR就可以捕获和表达各种AI模型特性
- 高阶IR的目标是建立控制流及算子与数据之间的依赖关系,并为图优化提供接口,
- 完整的高阶IR,至少需要包括对计算图的表示,如使用DAG(Directed Acyclic Graph)和let-binding等形式来构建计算图。
- AI编译器中的数据(如输入、权重和中间数据)通常以张量(tensor)或 多维数组的形式进行组织。因此高阶IR还需要提供对数据张量和算子的支持,包括编译所需的语义信息,并为自定义算子提供可扩展性。
所以,用高阶IR设计的数据和算子灵活性和可扩展性更好,可以支持各种AI模型,更重要的是,高阶IR与硬件无关,可以用于各种硬件后端
低阶IR,主要设计用于各种硬件相关的优化和代码生成。因此,低阶IR应该注重设计细节,并以更细粒度的表示形式反应硬件特性,准确表示硬件相关的内存布局、并行化模式等优化选项。
此外,低阶IR还应该在编译器后端中兼容使用成熟的第三方工具链,利用已有编译器工具完成通用优化和代码生成,并将指令选择、寄存器分配等低级优化留给LLVM等下游编译器完成,重点关注下游编译器未涵盖的优化方法。
由上图AI编译器结构图可见,AI编译器的输入是来自深度学习框架的AI模型,针对AI模型的编译、优化过程大体分为两个阶段。第一个阶段是与硬件平台无关的前端优化,第二个阶段是与硬件平台相关的后端优化和代码生成。
第一阶段:
首先,前端从深度学习框架中获取AI模型作为输入,并通过模型导入接口,将深度神经网络的高级规范转换为AI编译器特有的高阶/图IR。此外,前端需要实现各种格式转换,以支持不同框架中的不同格式。高阶IR通常采用有向无环图形式。其中的每个节点代表一个计算操作,每条边代表操作之间的数据依赖关系。因此,前端可以在高阶IR上使用结合通用编译器优化和AI特定优化的图优化方法,对图中的算子做融合操作并与优化数据布局,以减少冗余计算和内存访问,提高高阶IR的效率。在前端优化之后,将生成优化的计算图。
第二阶段:
将高阶IR转换为低阶IR,后端可执行硬件相关的后端优化。后端可以利用AI模型和硬件特性的先验只是,通过定制的优化pass,增强数据局部性,优化调度,并充分利用硬件平台的并行性,将优化后的代码实现映射为AI芯片的可执行指令。常见的硬件相关的优化包括硬件intrinsic映射、内存延迟隐藏、并行化及针对循环的优化等。为了在大型优化搜索空间中确定最佳参数设置,在现有的AI编译器中广泛采用自动调度(如多面体模型) 和自动调优(autoTVM)。优化后的低阶IR通过JIT(Just In Time)或AOT(Ahead Of Time)编译,生成针对不同硬件目标的代码。
------华丽的分割线------
终于,终于,对常规的编译器以及AI编译的介绍暂时告一段落,下面来进入主题 ---- TVM的整体架构
TVM的提出是为了解决深度学习框架和硬件后端适配的问题。
TVM是一个端到端的全栈编译器,包括统一的IR堆栈和自动代码生成方法,其主要功能是优化在CPU、GPU和其他定制AI芯片上执行的AI模型,通过自动转换计算图,实现计算模式的融合和内存利用率最大化,并优化数据布局,完成从计算图到算子级别的优化,提供从前端框架到AI芯片、端到端的编译优化。
通过TVM只需要花费少量工作即可在移动端、嵌入式设备上运行AI模型。
总览TVM系统结构图:
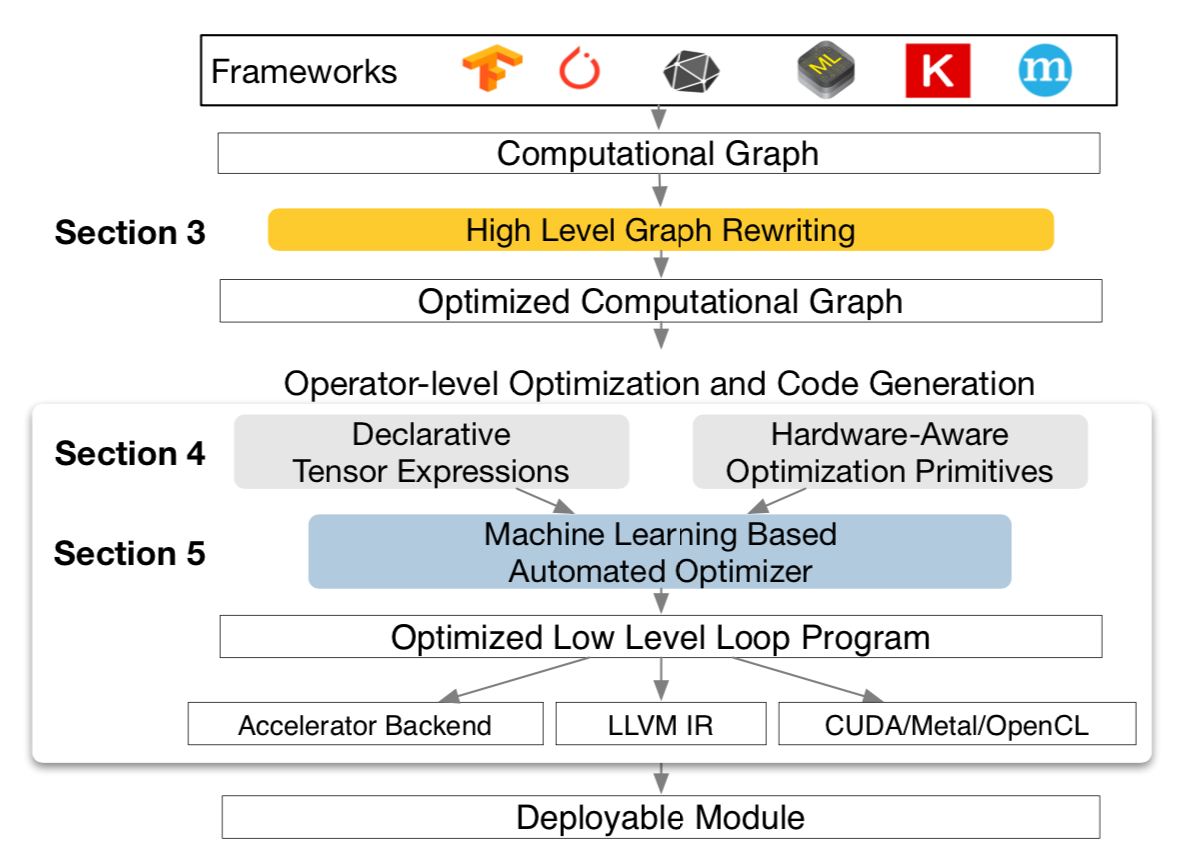
TVM以AI模型作为输入,首先将其转换为计算图,然后执行高级数据流重写,为计算图生成优化图。
算子级优化模块为优化图中的每个融合算子生成高效代码,并以声明式张量表达式指定算子。
TVM为给定硬件目标算子建立了可能的优化集合,这形成了巨大的搜索空间。因此,TVM使用机器学习的代价模型搜索优化算子。
最后,系统将生成的代码打包到可部署模块中。






